Huo Z, Gu B, Huang H. Training neural networks using features replay[C]//Advances in Neural Information Processing Systems. 2018: 6659-6668.
1. Overview
1.1. Motivation
- the computational time of the backward pass is about twice of the computational time of the forward pass
- existing methods removing backward locking work poorly when DNN is deep
In this paper
- propose a novel parallel-objective formulation for the objective function of the neural network
- introduce features reply algorithm
- prove it is guaranteed to converge
- experiments to demonstrate the proposed method achieves faster convergence, lower memory consumption and better generalisation error
2. Algorithm

2.1. Formulation
parallel-objective loss function

optimal solution

2.2. Breaking Dependency
2.2.1. New Formulation
- each module is independent and updated at the same time
- module k keeps a history of its input with size K-k+1
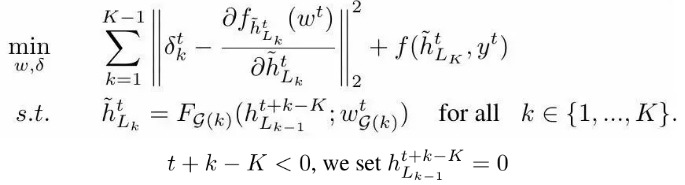
2.2.2. Approximation

2.2.3. Gradient inside Each Module

2.2.4. Pass Gradient

- module k sends to the gradient below module k-1 for the computation of the next iteration
2.3. Procedure


3. Experiments
3.1. Implementations
- CIFAR-10 and CIFAR-100
- ResNet
- random cropping, random horizontal flipping and normalizing
- K modules is distributed across K GPUs
3.2. Sufficient Direction Constant σ

- divide ResNet164 and ResNet101 into 4 modules
- σ > 0 all the time. Assumption 1 is satisfied such that Algorithm 1 is guaranteed to converge to the critical points of for the non-convex problem
- σ of lower modules are small at the first half epochs. The variation of σ indicates the difference between the descent direction of FR and the steepest descent direction
- small σ at early epochs. help method escape from saddle points and find better local minimum
- large σ at final epochs. prevent method from diverging
3.3. Memory Consumption

3.4. Generalization
